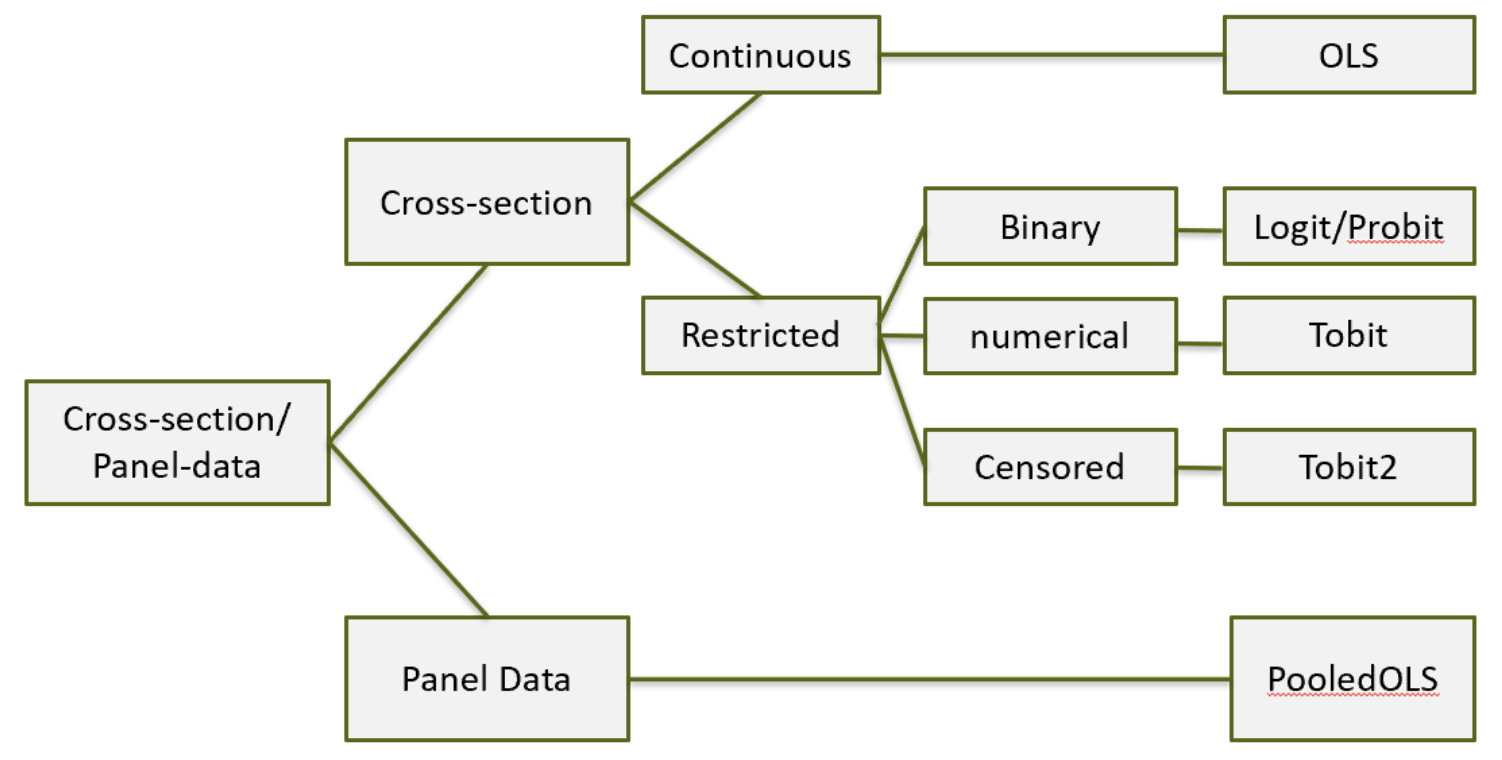
計量経済学を学ぶときに最も大事なのは全体像がどうなっているのかをつかむこと。ここがわからないと、今なにをやっているんだろう、と困惑してしまいます。
データ分析を始めたけど、いったい何をやればいいかがわからないよ、、、
分析においては、最初の一歩がとっても肝心!まず対象としている変数の観察から始めよう。分析対象やデータの構造に応じた手法を用いることで、正しい結果が出るだけでなく、見通しも立てやすくなり、分析後の問題も減らせるよ。
データを実際に分析する際には、全体像を考えながら順に手順を踏むことで正しい示唆をデータから得られるようになります。
ここでは、そのモデル決定の全体像をまとめてみたいと思います。
前提(実証分析とは)
実証分析とは、なんらかの(経済)モデルや効果の仮説をデータをもとに実証していく分析のこと。計量経済学では、この実証分析を行っているので、まず調べたい仮説を立てることから始める。たいていは過去すでになされた仮説やモデルを別の手法やらデータで実証するパターンが多いとのこと。
(ちなみに、この時点でデータをもとに実証する目的ではなく、予測が目的なら機械学習などの方が良いのだろう。)
スタートはデータを持っており、データクリーニングとエンコーディングは終わっているとする。(この部分はpythonなどでできる)
また書いてあるコードはstataのコードを用いている。
データの種類の確認
例とともに、データの確認の方法を見てみよう。
例:教育年数の所得への影響を知りたい。
実施したこと: y(所得)とeduc(教育年数)などのデータをcsv等からdtaに変換し、soc-capital.dtaに保存した。(dtaはstata独自のデータ形式)
*go to data directory
cd ../Data
*set log file
log using analysis1.log, replace
*use dataset
use soc-capital.dta
*discribe data
tab year
summarize y educ
describe y educ
browse結果:
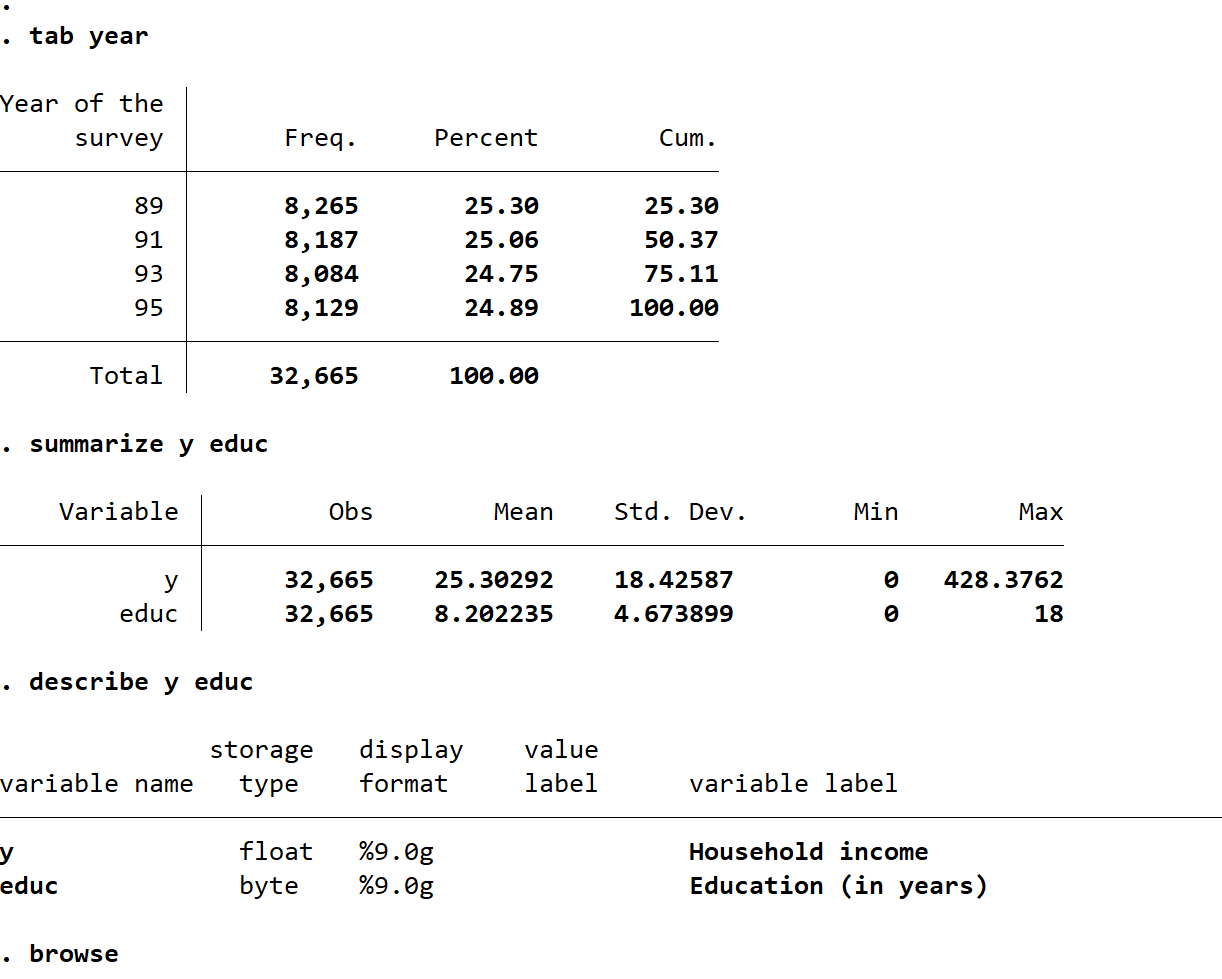
データを見ていき、観察をする。そして、それを以下のモデル決定図に当てはめていく。
データを見ることができたよ!所得と教育年数、それから調査の年があるね。
データ構造の次元と、yについて注目しよう。
ここからわかるのは、まずデータが3次元なのでパネルデータであることだね。また、yは制限されていて、後で確認するけど、これは見えないデータを含むセンサーデータだね。
モデル決定図
次に、データの形からどのようなモデルをまず使うかを決定しよう!
以下に画像で示したが、それぞれの枠の中にはそのデータの種類が書いている。そして最後の四角の中には利用する手法が記載されている。データに合わせて条件分岐をさせていくことで、末尾に書いてあるような手法を用いれば、データの種類に合った正しい分析結果を導くことができる
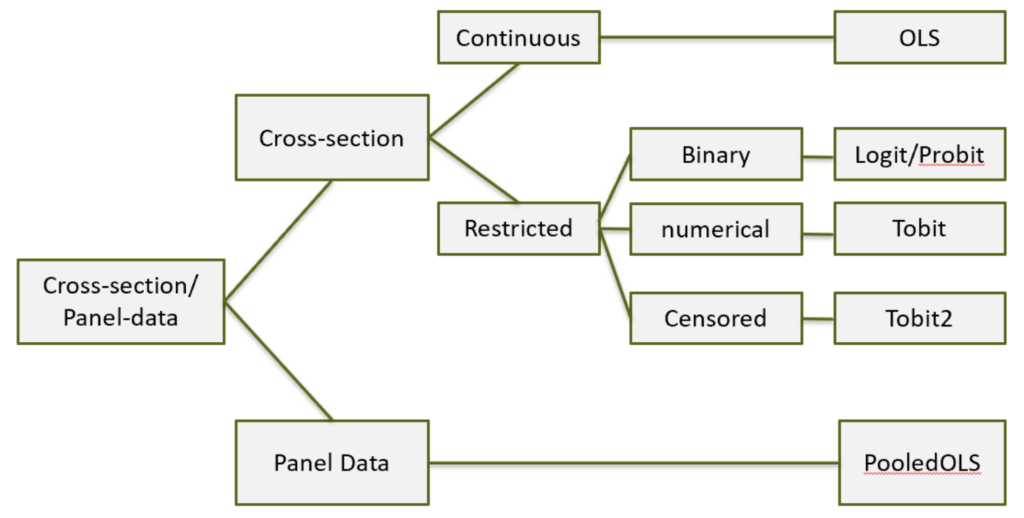
クロスセクションとパネルデータについて
まず、2次元的なデータを扱う場合、これをクロスセクションデータという。3次元的(つまり複数の時間ごとの複数の個体のデータ)の場合、パネルデータという。
パネルデータの場合
3次元的なデータを扱っていることがわかれば、Pooled OLSを用いることになる。手法はこれでOKなだが、大体のパネルデータは時間を扱っている。
時間を扱う場合には注意が必要だよ〜!
クロスセクションの場合にはあまり気にならなかったMulticollinearityという問題である。
Multicollinearity:A statistical concept where several independent variables in a model are correlated
需要の価格弾力性(price elasticity of demand) – $\epsilon$
需要の価格弾力性とは、ある財やサービスの消費の変化を、その価格の変化に関連づけた指標のこと。数式的には、
$$需要の価格弾力性 = 需要される量の変化率/ 価格の変化率$$
となる。変化率は通常、変化前の値を基準とする。この指標の意味は、価格が1%変化した時に、何%需要が変化するかということである。
また、供給についての場合は、供給の価格弾力性と呼ぶ。価格弾力性は価格が動いた時に、需要や供給がどのように動くかを理解するために経済学において用いられる。
例えば、1999年、2000年、2001年などの計測年がダミーデータとして入っている場合は、その3年の間の関連性を分析において排除しておかねばならない。年があれば間違いなくこの問題があるが、それ以外で気になる場合には、Variance Inflation Factor(VIF)というテストを行って確認しよう。
クロスセクションの場合
クロスセクションは簡単かな〜!
いいや、クロスセクションこそ、パネルデータよりも扱うデータの次元が少ない分、気をつけなくてはいけないよ!
クロスセクションの場合、もとめるyが何かでまず分岐する。
連続データの場合
OLSを用いる。
yが制限されている場合
それが2値データか、数値的なデータ(例えば、0<y<1, 0<y, 1<y<100など)か、センサーデータか、で分けられる。
センサーデータ:実際と観察が異なっているため見えないデータがあるもののこと。
例えば給与の場合、働いていない人の給与は見えないため0と表示されているが、実際の提示額は0ではないのでセンサーデータとなる。
基本的には2値データの場合が多いだろう。この場合は、Logit/Probitモデルを選択する。これらはIndexモデルといい、例えばLogitの場合、OLSの結果をロジスティック関数を使って0から1に収めることで、y=1である確率を表示できるようにする。
一方、数値的なデータの場合には、Tobitモデルを用いる。また、センサーデータの場合にはTobit2モデルを利用しよう。
まとめ
最後にもう一度この図を見て、応用をしてみよう!
最初に扱った所得と教育年数の例で言えば、パネルデータなのでPooledOLSを使えばいいね。
しかし、もし調査年の変数がなく、それがクロスセクションだったとしたら、yは制限付きであり、センサーデータだったので、Tobit2モデルを用いればいいとわかるね。
なんとなく分析の一歩目が踏み出せそうだよ!

コメントを残す コメントをキャンセル